Meta's latest audio model, SPIRIT LM, enables AI to not only be eloquent but also "expressive with both voice and emotion"!
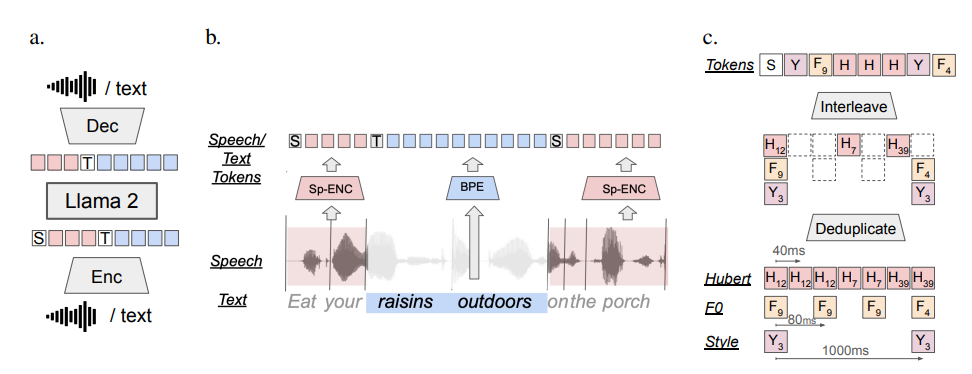
Meta AI has recently made a significant open-source release of the basic multimodal language model named SPIRIT LM. This model can freely mix text and speech, opening up new possibilities for multimodal tasks involving audio and text.
SPIRIT LM is based on a pre-trained text language model with 7 billion parameters. Through continuous training on text and speech units, it extends to the speech modality. It can understand and generate text like a text large model, and at the same time, it can also understand and generate speech. It can even mix text and speech together to create various amazing effects! For example, you can use it for speech recognition to convert speech into text; you can also use it for speech synthesis to convert text into speech; and you can use it for speech classification to determine what emotion a segment of speech expresses.
 Even more impressively, SPIRIT LM is especially good at "emotional expression"! It can recognize and generate various different speech intonations and styles, making the AI's voice sound more natural and emotional. You can imagine that the speech generated by SPIRIT LM is no longer that cold robotic voice but sounds like a real person speaking, full of joys, sorrows, angers, and happiness!
Even more impressively, SPIRIT LM is especially good at "emotional expression"! It can recognize and generate various different speech intonations and styles, making the AI's voice sound more natural and emotional. You can imagine that the speech generated by SPIRIT LM is no longer that cold robotic voice but sounds like a real person speaking, full of joys, sorrows, angers, and happiness!
To enable AI to better be "expressive with both voice and emotion", Meta's researchers have specifically developed two versions of SPIRIT LM:
"Base Version" (BASE): This version mainly focuses on the phoneme information of speech, that is, the "basic components" of speech.
"Expressive Version" (EXPRESSIVE): In addition to phoneme information, this version also incorporates intonation and style information, which can make the AI's voice more vivid and expressive.
So, how does SPIRIT LM achieve all of this?
Simply put, SPIRIT LM is trained based on Meta's previously released super-powerful text large model, LLAMA2. The researchers "fed" a large amount of text and speech data to LLAMA2 and adopted a special "interleaved training" method to enable LLAMA2 to learn the rules of both text and speech simultaneously.
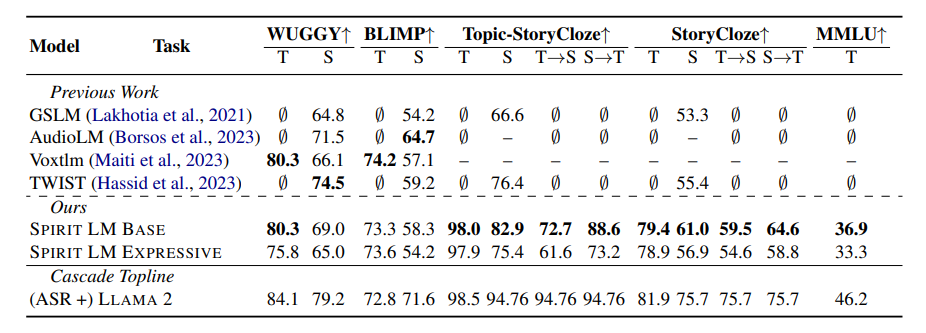
To test the "emotional expression" ability of SPIRIT LM, Meta's researchers have specifically designed a new test benchmark - the "Speech-Text Sentiment Preservation Benchmark" (STSP). This test benchmark contains various speech and text prompts expressing different emotions and is used to test whether an AI model can accurately recognize and generate speech and text with corresponding emotions. The results show that the "Expressive Version" of SPIRIT LM performs excellently in terms of sentiment preservation and is currently the first AI model capable of preserving emotional information across modalities!
Of course, Meta's researchers also admit that SPIRIT LM still has many areas that need improvement. For example, SPIRIT LM currently only supports English and will need to be extended to other languages in the future; the scale of the SPIRIT LM model is not large enough and will need to continue to be expanded in the future to enhance the model's performance.
SPIRIT LM is a major breakthrough by Meta in the field of AI. It has opened the door for us to the "expressive with both voice and emotion" AI world. It is believed that in the near future, we will see more interesting applications developed based on SPIRIT LM, enabling AI to not only be eloquent but also express emotions like a real person, and communicate with us more naturally and cordially!