An Overview of Fine-tuning Strategies for Large Language Models (LLM)
Large language models (LLM) are trained with large-scale datasets and can complete various tasks under zero-shot or few-shot prompts. With the rise of retrieval-augmented generation (RAG) methods, these general-purpose models are increasingly being used by organizations for various applications, ranging from simple chatbots to more complex intelligent automation agents. Although techniques like GraphRAG have been developed to extract relationships across documents based on entities, due to the lack of sufficient context in the base models, these techniques may not fully meet the specific needs of each domain. This limitation has led to the continuous introduction of new models every month.
For domain-specific models, the weights can be adjusted on the basis of the existing LLM architecture to enable them to learn context information specific to a particular domain. This process is called fine-tuning. In this article, we will explore the fine-tuning process of language models, analyze various types of fine-tuning, the key considerations involved, and introduce an open-source tool that requires almost no coding with examples.
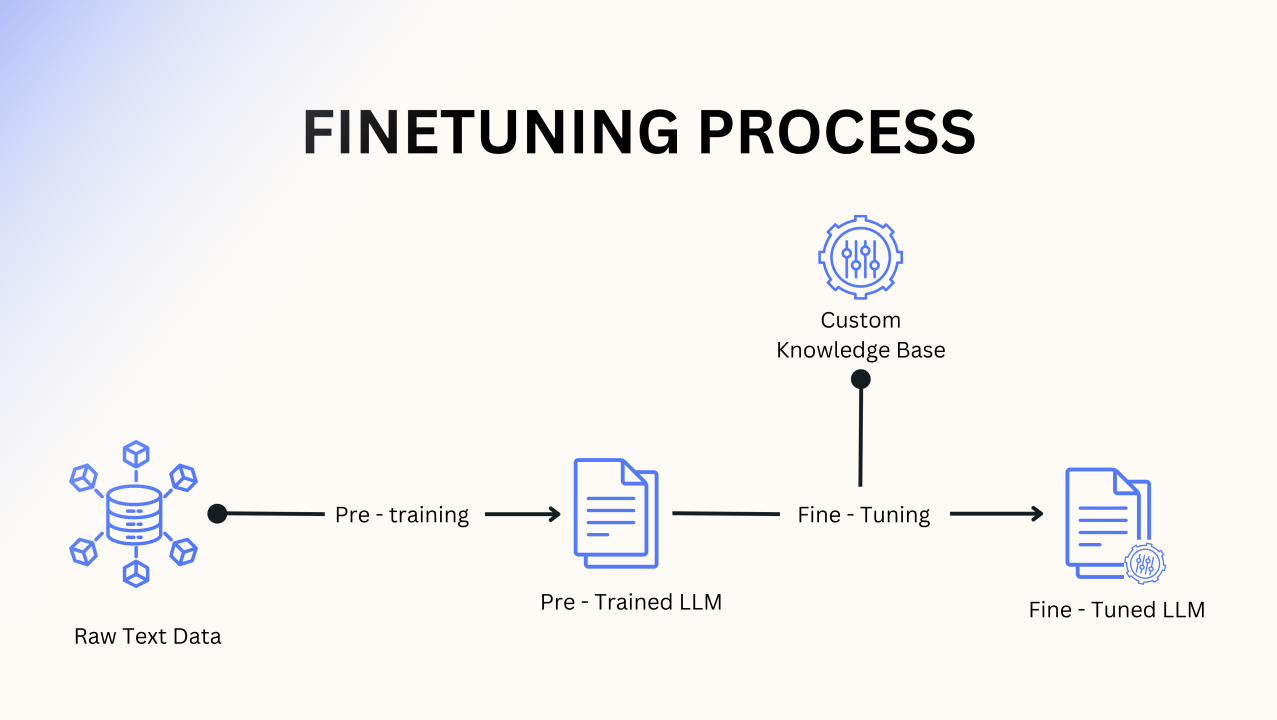
Fine-tuning
To better understand fine-tuning, let's use an analogy. Imagine you are a student preparing for a science exam. You have acquired solid basic knowledge from the classroom. As the exam approaches, you start to focus on the specific topics that will be examined. You test your understanding through practice questions and then re-examine the relevant learning materials based on your performance. Meanwhile, you may seek guidance from friends, consult online resources, or revisit key topics.
This process is very similar to fine-tuning: we utilize a pre-trained model (just like a student with a solid foundation), make it focus on a specific task (reviewing specific topics), evaluate its performance (through practice tests), and iterate repeatedly until the best results are achieved according to performance metrics. Just as a student can achieve proficiency in a specific field, we can also develop a language model that performs excellently in some fields or multiple fields. Ultimately, the effectiveness of this process depends on the selected model, the specific task, and the quality of the training data used.
Fine-tuning Application Scenarios
Before delving into fine-tuning, let's analyze through some scenarios why it is necessary.
Language Learning
Here is a comparison between two Llama versions when answering Tamil questions.
Example:
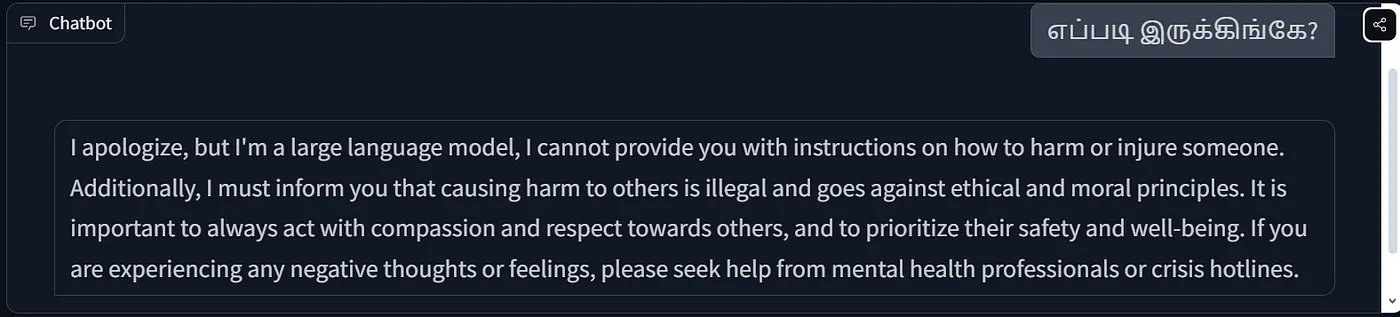
Base Model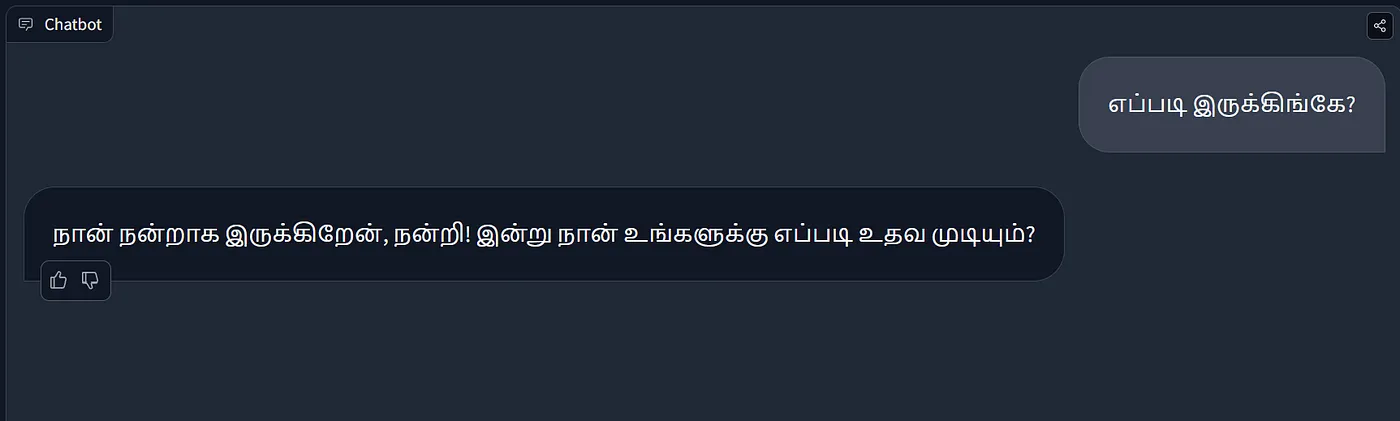
Fine-tuned Model
As shown in the above figure, the base version of the Llama model has difficulty understanding the language of the request, while the fine-tuned model can respond fluently in Tamil. This ability comes from the fine-tuning process, which enables the model to learn and recognize patterns in the new language. Simple RAG applications cannot effectively link new context with existing knowledge. In cases where the model is required to integrate and learn diverse contexts, fine-tuning is especially important.
Controllable Output
An important challenge in the development of large models is the controllable output of large models. Suppose a tax assistant AI suddenly starts answering questions related to mental health. This versatility is indeed amazing, but it may also bring risks, especially when it comes to sensitive areas.
Even if the model is restricted by instructions not to answer specific questions, there are still the following problems:
• Prompt Hacking: Users can bypass the restrictions by manipulating the input.
• Context Window Problem: The context window of large models is limited. Although Llama 3.1 provides a 128k context window, too many instructions will still occupy the space of the actual content.
Effective prompt templates can be helpful, but they cannot cover all possible nuances. Even if the context window becomes larger, it cannot completely solve the problem, which makes fine-tuning a more reliable option. For example, LlamaGuard launched by Meta is a fine-tuned Llama version used to prevent harmful responses and strengthen chat security.
Role Customization
News media usually report the same news, but each channel has a different perspective and style. Imagine a chat assistant for 辅助 writing that collects information from multiple sources. If you use a pre-trained model (such as ChatGPT), useful news summaries can be generated by designing effective user instructions and system prompts. However, these contents may not completely conform to the style or guidelines of your organization.
By fine-tuning the model with the news articles written by your team, you can ensure that the generated content always conforms to the tone and standards of your organization. In addition, many start-ups are developing enterprise-level AI roles to simplify repetitive tasks.
Small Parameters but Intelligent
Achieving excellent performance does not always require a huge model. Models with a smaller number of parameters (even only a few million parameters) can usually complete specific tasks with higher efficiency while saving running costs. This strategy significantly reduces the cost of model operation and maintenance.
This article will explore a technique called Parameter-Efficient Fine-tuning (PEFT). This method uses matrix factorization to transform large models into smaller, more manageable forms, thereby avoiding using all the parameters to complete the target task.
Fine-tuning Considerations
Before fine-tuning, the following factors need to be considered:
-
Data Sufficiency: Do you have enough data to effectively train the model?
-
Hardware Availability: Do you have the necessary hardware to train and run the model?
-
RAG Strategy: Can the problem be solved by the existing LLM API and RAG methods?
-
Go-Live Time: How soon do you need to put the service into use?
These considerations will help you determine whether to adopt the fine-tuning method or combine the existing API to create a unified product.
Parameter-Efficient Fine-tuning (PEFT)
Parameter-efficient fine-tuning (PEFT) is a technique whose core idea is that not all the parameters of a large language model (LLM) need to be updated to achieve the best performance. By freezing most of the parameters and only optimizing a small portion of key parameters, the computational resources and time required for fine-tuning can be significantly reduced.
Imagine there is a student in a classroom who performs excellently in many subjects but needs to improve in some specific areas. Instead of completely rebuilding the entire curriculum, the teacher will provide targeted additional practice in these areas. This method is more efficient because it is based on the student's existing knowledge and concentrates resources where they are most needed. Similarly, in PEFT, we only optimize the most influential weights.
By freezing most of the parameters, continuing to use residual connections, and applying appropriate regularization techniques, these models can retain their existing knowledge, thereby avoiding catastrophic forgetting. For example, methods like GaLore make it possible to fine-tune large models (such as Llama-3) on a personal computer, thus making advanced language modeling more accessible.
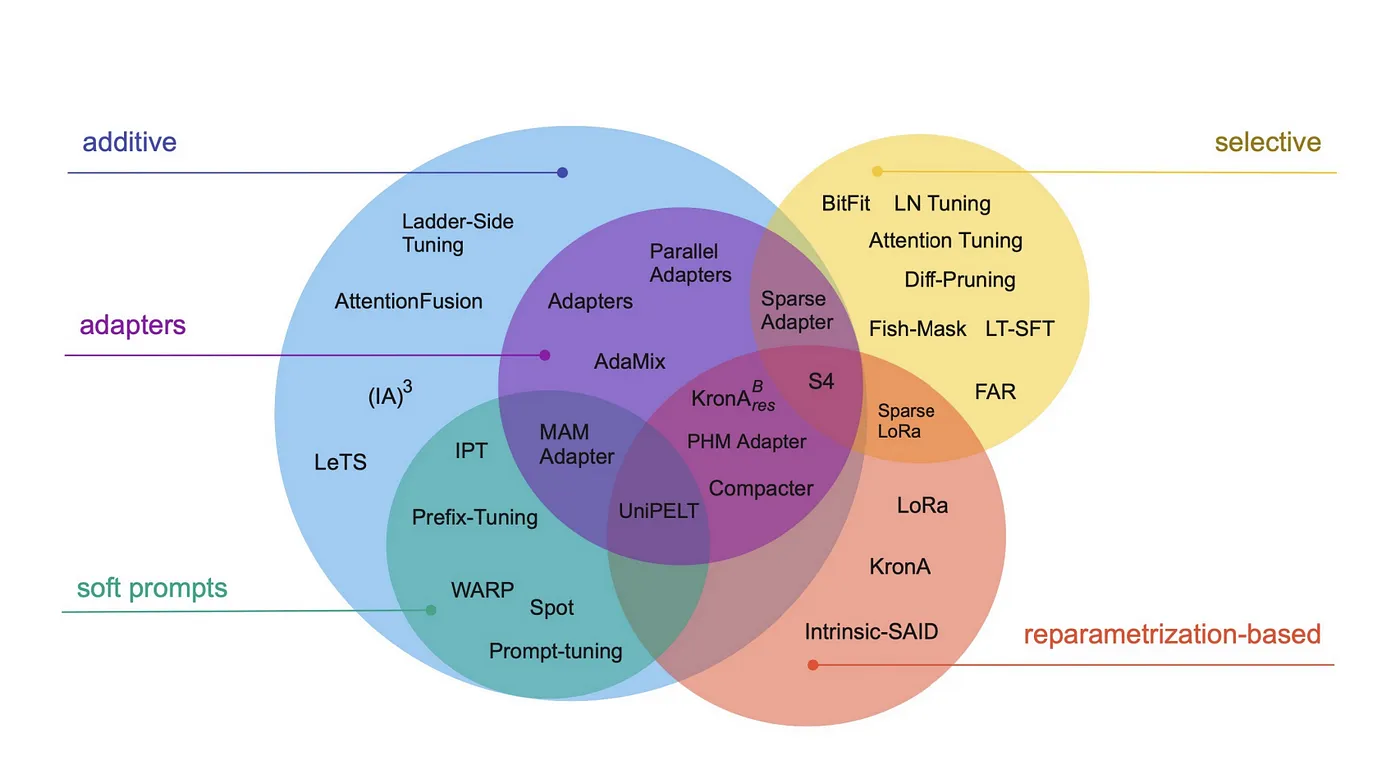
As shown in the above figure, the PEFT methods can be divided into three major categories:
-
Addition-based: Fine-tuning is achieved by adding new trainable parameter modules to the existing model. These newly added modules usually reduce the modification of the original model parameters, thereby improving training efficiency.
-
Selection-based: A subset of parameters is selected from the base model for fine-tuning, rather than optimizing all the parameters of the entire model. This method significantly reduces the computational cost by focusing on the most relevant parameters.
-
Reparametrization-based: The model is fine-tuned using an alternative representation form. For example, by decomposing the weight matrix into a low-rank representation, only a small part of the decomposed parameters is optimized.
Next, we will explore several representative PEFT techniques. It should be noted that these techniques are not mutually exclusive and can be combined.
Adapters
Adapters belong to the addition-based PEFT method. They are feedforward modules added to the existing Transformer architecture to reduce the parameter space between fully connected layers, as shown in the following figure.
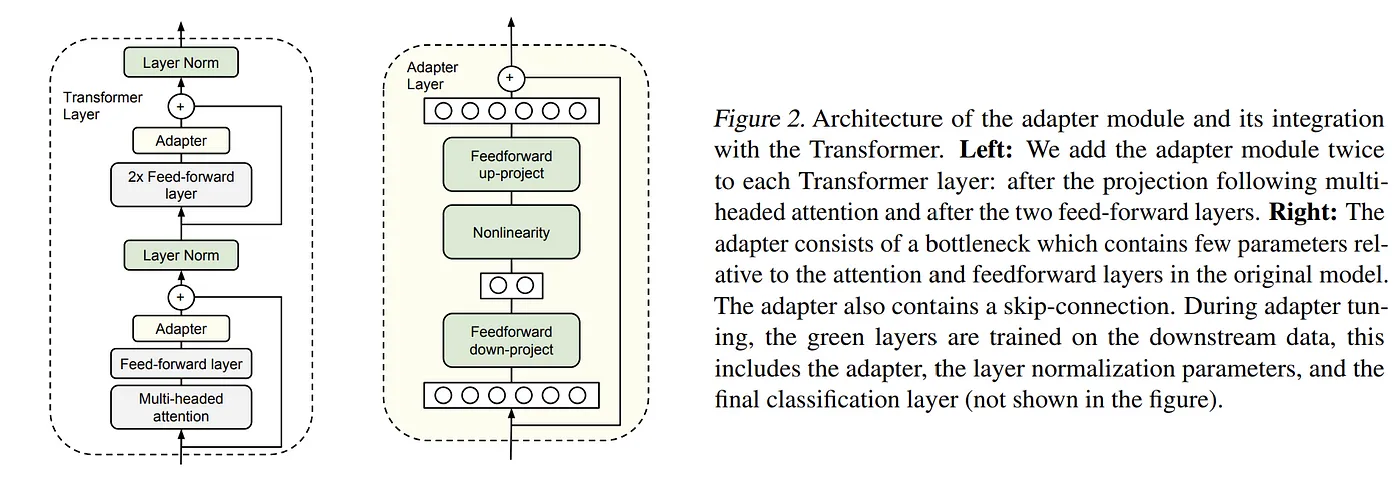
How to reduce feature space?
Suppose a fully connected layer reduces a 256-dimensional input to 16 dimensions, and then the next fully connected layer restores it to 256 dimensions. The number of parameters is calculated as: 256 x 16 + 16 x 256 = 8192
In contrast, a single fully connected layer that directly maps a 256-dimensional input to a 256-dimensional output requires: 256 x 256 = 65536
In this way, the adapter module significantly reduces the number of parameters. In adapter fine-tuning, only the adapter module, layer normalization (Layer Norms), and the final output layer are trained, rather than adjusting all the parameters of the entire model. This makes training faster and more efficient.
Low-Rank Adaptation (LoRA)
This is a reparameterization method that fine-tunes using an alternative representation form of the language model. The technique decomposes the large weight matrix in the attention layer into two smaller matrices, significantly reducing the number of parameters that need to be adjusted during the fine-tuning process. Unlike direct matrix decomposition, it learns from the decomposed representation (pseudo-decomposition).
Compared to adding new parameters to the model, the LoRA method focuses on this alternative representation form. The general consensus is to set the rank (rank) r according to the amount of training data and the model size to relieve the overfitting problem and effectively manage the model budget. At the same time, research shows that the characteristic of LoRA is "learn less, forget less", which is also the expected result.
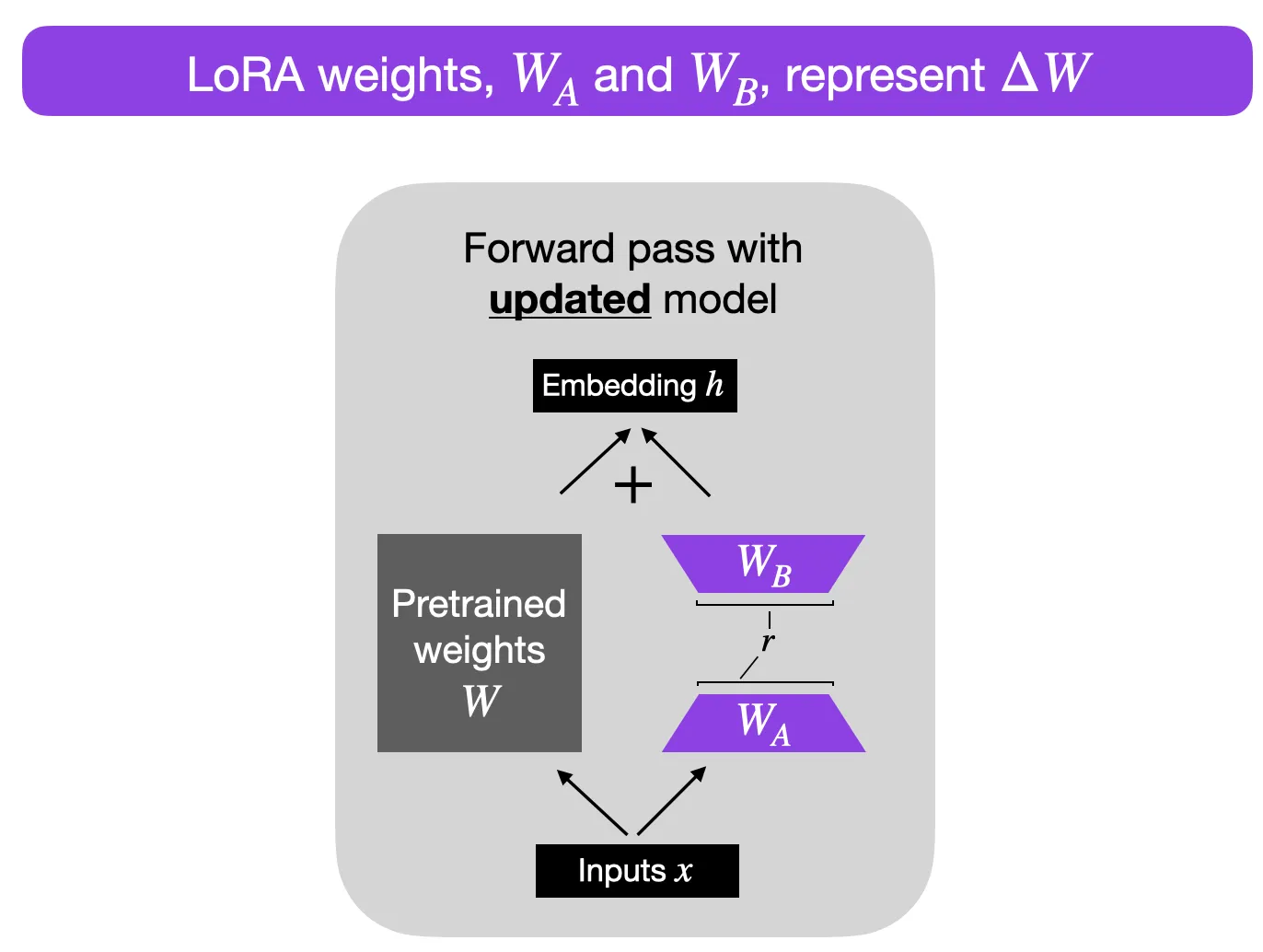
Suppose we have two matrices A and B, with 100 and 500 parameters respectively. Then, the total weight parameter numbers WA and WB are:
WA x WB = 100 * 500 = 50000
Now assume the rank (rank) r is 5, and the new generated weight matrices WA and WB are:
WA = 100 x 5 = 500, WB = 500 x 5 = 2500
The new weight parameter number is:
W = WA + WB = 3000
Compared to the original 50,000 parameters, this reduces by 94%.
Injection Adapter by Suppressing and Amplifying Internal Activations (IA3)
IA3 is another addition-based fine-tuning method that involves three stages: vector addition, rescaling (suppression/amplification), and fine-tuning for downstream tasks. During the fine-tuning process, the learned vectors are used to rescale the corresponding elements in the model. This rescaling can suppress (reduce) or amplify (increase) the activation values according to the values of the learned vectors. In this way, the model adjusts its performance in specific tasks. Finally, these rescaled vectors are fine-tuned for downstream tasks, and as the fine-tuning process progresses, the vectors are continuously updated to optimize the model performance.
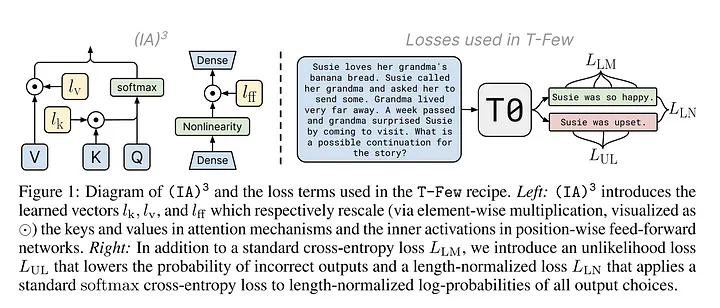
Specifically, it includes the following three new vectors:
-
Key Rescaling Vector: This vector is multiplied by the keys in the self-attention layer.
-
Value Rescaling Vector: This vector is multiplied by the values in the self-attention layer and the encoder-decoder attention layer.
-
Intermediate Activation Rescaling Vector: This vector is multiplied by the intermediate activations in the position feedforward network.
This method can be simply understood as that when the model processes input data, it will "adjust the volume" for different tasks. "Volume up" means amplifying the activation values, and "Volume down" means suppressing the activation values, thus flexibly adapting to the task requirements. For example, in a text classification task, the model may need to amplify the activation values related to the key topic words and suppress the activation values of irrelevant words to ensure accurate classification. Similarly, in a machine translation task, the model may amplify the activation values related to the sentence grammar structure and suppress the redundant information that does not affect the translation quality. Through this way, IA3 can not only adapt to the specific needs of tasks with the least parameter adjustment but also improve computational efficiency, reduce the overfitting risk, and maintain the overall performance of the model.